Introduction
As we always say at Infosecnirvana, “Every Attacker leaves behind a trail”. Identifying the trail in an organization’s infrastructure is the main goal of Incident Detection and this is where all the cutting edge technology, talented people and mature processes come together. From Perimeter protection devices like Firewalls (Both Network & Application), IDS/IPS, Breach Detection Systems (FireEye, Fidelis, etc.), to Endpoint Protection Systems like AV-AS, HIDS, there are a host of security management systems that help to detect potential Security incidents needing action. Even Physical Security systems, Industrial control systems, etc. can be detecting Incidents. Never before has incident detection been important than today and it comes as little surprise when organizations globally want to look at Incident Detection as an important tenet in their security posture. But before embarking on an Incident detection journey, it is important to understand the basics of Incident detection and how it forms the foundations of CSIRT functions world over. So let us start with the introduction.
Security Events are not Security Incidents: Confused??? Don’t be. Yes, Security events are not Security incidents. Both are different and here’s Why? Security products and technologies generate several actionable items. Helpdesk, Consumers, Business, Audit and compliance and even a Security guard reports Security issues. All these together are “Security Events”. However, not all of these events are fit enough to become Security Incidents. The Events have to be carefully validated for Relevance, Authenticity, Impact and Urgency. Only after this initial validation does an event qualify as a Security incident worth investigating. In short “A Security Incident is a Qualified Security Event”. If a team where to focus on every single Security event as a Security Incident, it will be an Operational nightmare. Hence it is important to perform Event Management or Event Handling.
Event Management: Every organization should have an effective Event Management process. The Event management philosophy should be “Many inputs (Event Reporting) but One Output (Incident)”. At a broad level there are 2 major Input sources to a Central Event Management system. They are described below:
- Automated Event Reporting: Most of the Security tools and technologies today generate several Security events daily. However, it is always difficult to individually handle these events when there are several point products in the market today. But, with the advent of SIEM, gathering, correlating and real-time alerting of these Security events is now possible. In SIEM parlance, this is done using “Use Cases”. Years back, we published a post on “Use Case Development Framework for SIEM” which went in enough details on how to build Use Cases on SIEM. This Automated Event reporting thus becomes the most important input into the Central Event Management function.
- Manual Event Reporting: Anyone from the Business, Legal, Consumers, End Users etc. can report potential Security events to an organization. Generally, most of the organizations have a IT Helpdesk as the central reporting desk for such issues. The reporting is typically done through and email system or through a phone call. Several organizations have an online self help ticketing system to report such events too. However, these have to be handled manually.
Event Qualification:
Once the events are reported automatically or manually, the next step is Event Qualification. Before making a determination whether the event is an Security Incident or not, a few deterministic questions need to be answered. Some of those are listed below:
- Date – Date of event discovery
- Time – Time of event discovery
- Time Zone – Time zone of the event source is critical when systems or businesses are geographically dispersed
- How was the event discovered?
- What is the impact of this event and what locations are impacted?
- Is the event ongoing?
- Event Reporter contact information?
- Type of data or systems affected (if available)
Based on the responses, an initial determination can be made about the nature of the event. If this event is a Non-Security related event, they it can be routed to the respective teams for further investigation and resolution. If the event is indeed a Security related, it is raised to the Incident Detection & Response team or the CSIRT team as a Security Incident for further investigation and response.
After generating a Incident…
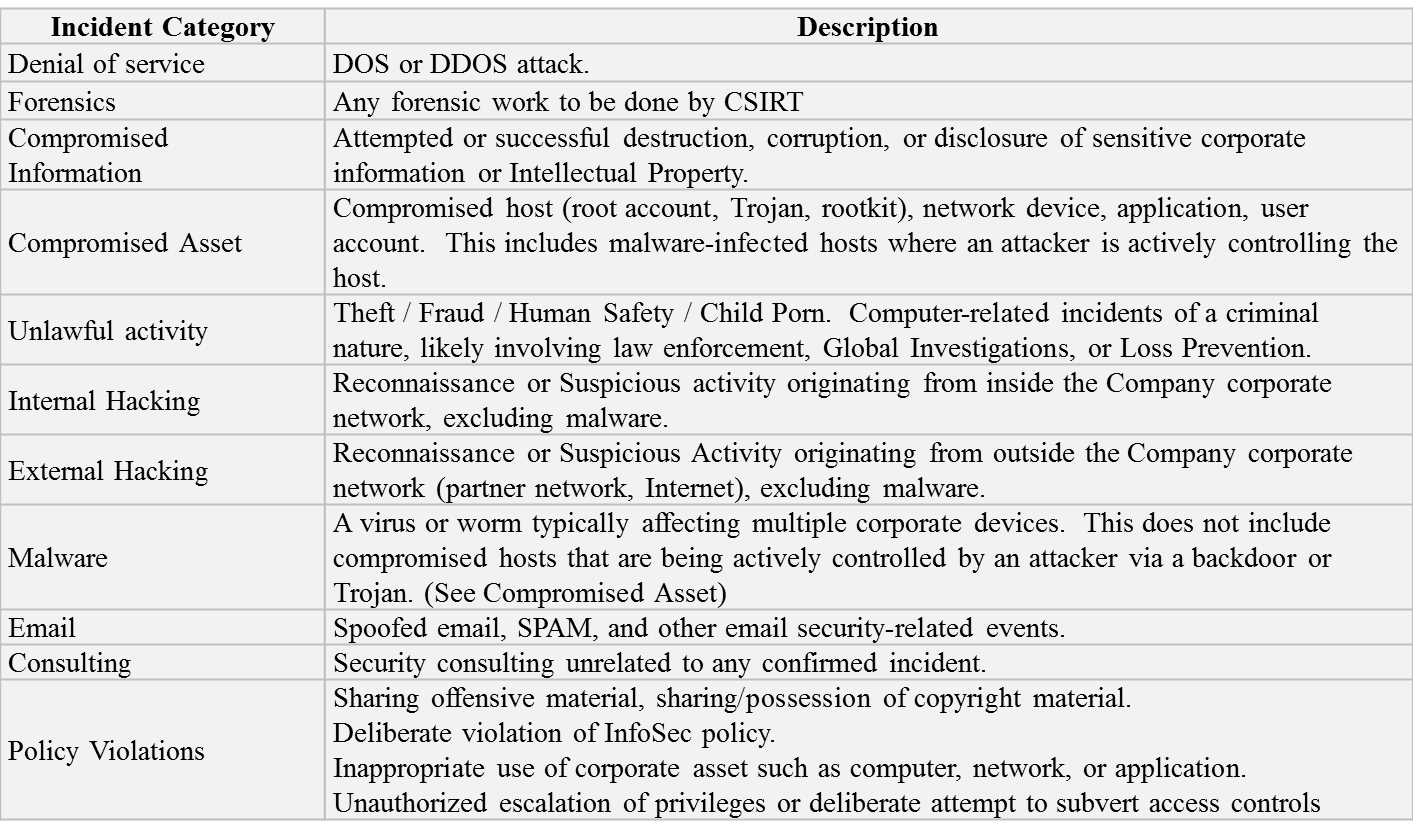
Once an Incident is generated from Event/Events, it has to be classified and categorized. This is the main function of Incident Classification function.
Go back or Continue reading Part 2 – Incident Classification