Incident Response is a key component of any organization serious about Cyber Security. However, many organizations are faced with the challenge of building and maintaining an “efficient” IR function or CSIRT. In our definition, an IR function is a perfect amalgamation of three major things – Well defined Process, Qualified People and appropriate tools & technologies. At InfosecNirvana, we have posted several things related to SIEM, Security Investigation and Log Management, however we have not spent considerable time in the IR side of things. This blog post aims to introduce you to our take on how an IR function should be.
Our IR Framework:
There are several IR frameworks in the internet, the most popular ones are the NIST framework and the SANS framework. Though the approaches are similar they are different in practice. Hence, we have tried to build a very generic framework that can be used by all the organizations that want to set up a IR function. The framework is as below:

The IR framework depicted here consists of 6 major functions. They are as follows:
- Incident Detection: – You can only respond to what you can see.
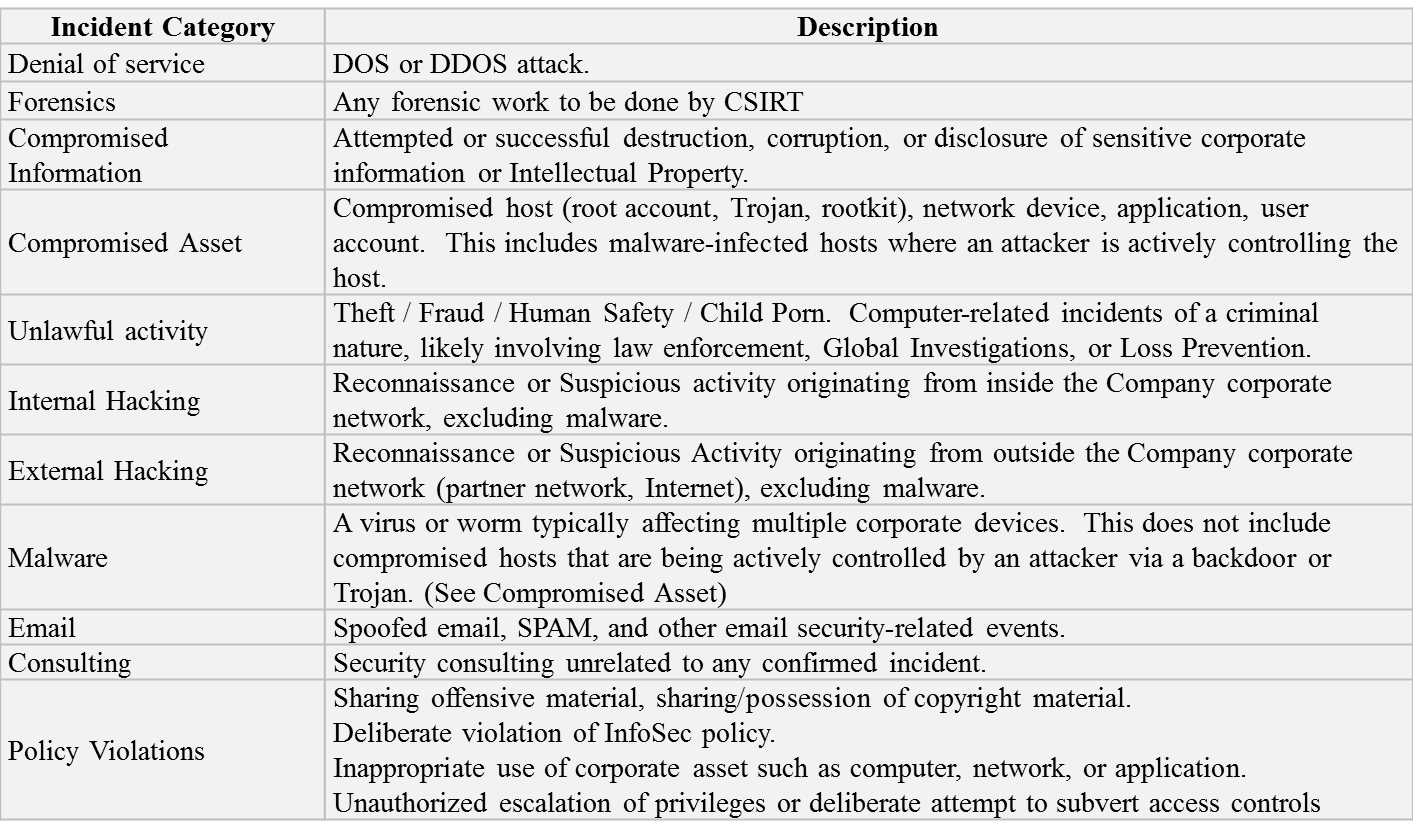
- Incident Classification: – Know where you are going, what you are dealing with.
- Incident Handling: – Handle with care
- Incident Containment:- Stop the bleeding
- Incident Recovery: – Get it back up and running
- Continuous Improvement: – Never stop learning and improving
Each of these functions listed above have a heady mix of Process, People and Technology. Several organizations have varied definitions for each of these function, but in this post, we are trying to make them as generic and all-encompassing as possible. Since a single post does not do justice to the readers, we have decided to split this into several sections for easy access and readability. Below are the links that explore each of these functions in detail. Feel free to comment in these individual sections so that discussions stay on topic.
- Part 1 – Incident Detection
- Part 2 – Incident Classification
- Part 3 – Incident Handling
- Part 4 – Incident Containment
- Part 5 – Incident Recovery
- Part 6 – Continuous Improvement
Until next time… CIAO!!!!