Introduction:
As discussed in Part 1 – Incident Detection, once the incident is detected, it needs to be categorized appropriately for Type, Severity and Impact so that necessary response actions can be taken. Incident Classification as such has two major parts to it – One is the Incident Categorization and the other is the Incident Severity Rating. Categorization assists in putting the events in to a common bucket for better coordinated and consistent handling while the Severity ratings assist in assigning a “sense of urgency” to the Incident detected. Without Incident Classification, a CSIRT function can quickly disintegrate into a pile of Operational mess. In fact, many organizations struggle with this aspect of CSIRT function. Hence, In this post, we will try to help readers with a simple and practical approach that we have seen work when it comes to Incident Classification.
Incident Categorization:
As mentioned at the beginning of the post, Categorization is similar to bucketing. However, the biggest question organizations face is “How do I bucket incidents?”, “What reference can I use”.
To order this, I am going to use two popular categorization standards. One if the all famous NIST categorization standard, and the other is the FIRST categorization standard.
NIST Categories:
US Federal agency has been at the forefront of Incident detection and response and they have come up with Incident categories to assist in Incident reporting and response. In the diagram below, you can see the NIST categories listed.

FIRST Categories:
Apart from NIST, organizations like FIRST have also come out with several guidelines for Incident Categorization. The diagram below shows one of their examples (from Cisco) for Categorization.
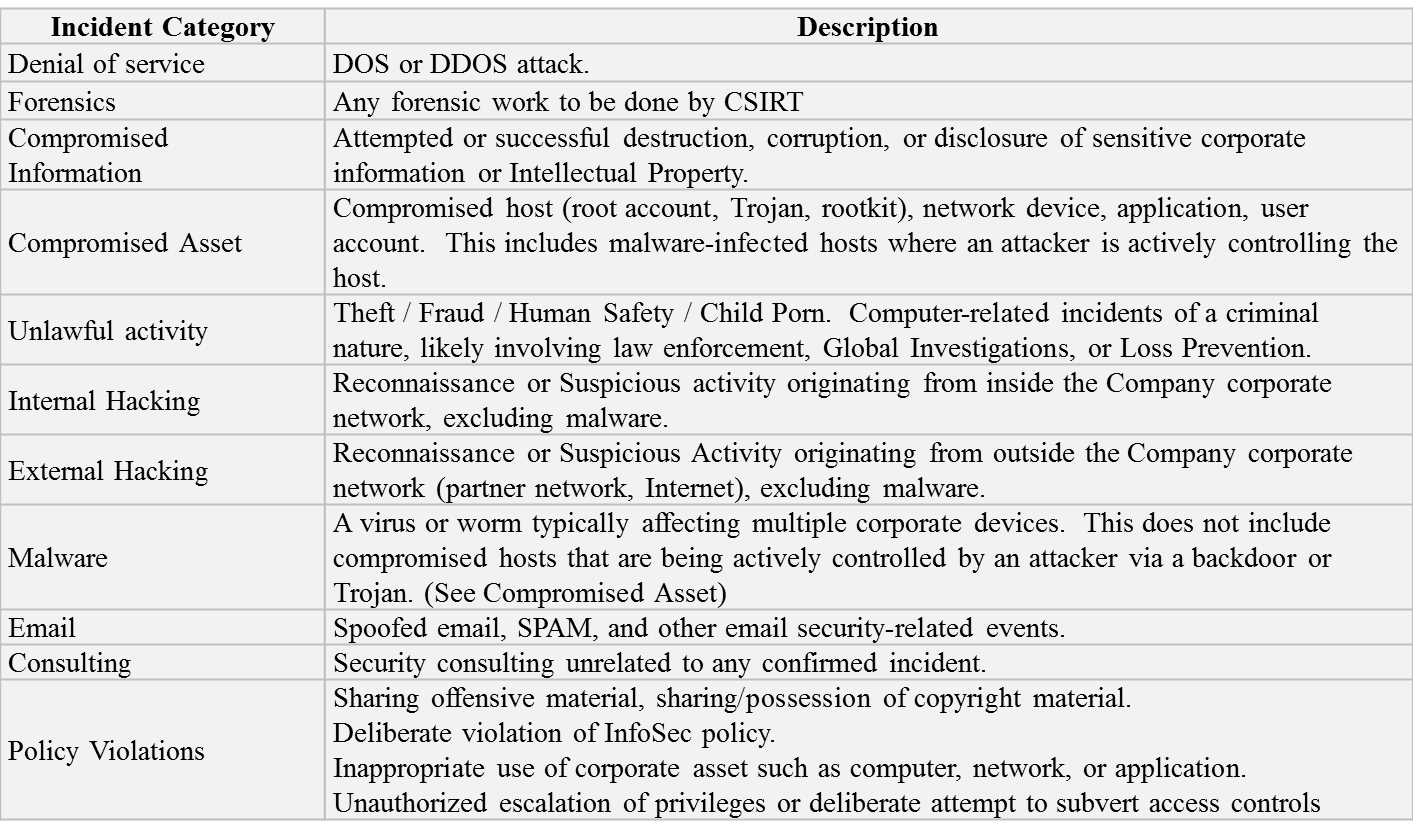
Now, both these models may not suit you entirely, but in general, we believe have at least 5 or 6 Categories will assist in better Incident Categorization. For example:
- CAT 1 – Unauthorized Access, Compromised machine, Compromised Asset, Data Theft, Espionage etc.
- CAT 2 – Denial of Service (DoS/DDoS)
- CAT 3 – Malware or Malicious Code
- CAT 4 – Reconnaissance or Scans or Probes etc.
- CAT 5 – Policy Violations or Improper Usage
- CAT 6 – Others or Uncategorised
This above categorization does a few things to combine the best of both worlds from NIST and FIRST and order them in a nice fashion in order of importance. CAT 1 being the most critical category and CAT 6 being uncategorised.
Incident Severity Rating:
Now that the Incident has been categorized, it is important to assign a Severity rating to the same. Severity ratings are typically done using Likelihood and Impact. One of the matrix which comes in quite handy is given below.

As you can see, the Severity rating is basically a 5 step scale from Very Low to Critical. It has Impact and Likelihood as a matrix to help decide the severity. Both Impact and Likelihood typically arbitrary and left to the judgement of the person handling the Incident. However, many organizations tend to define this as much as possible.
Impact, a more business risk related term can be quantified by using Asset Values, Data Sensitivity Classifications, etc. while Likelihood is a more technical input arising out of the “Incident” itself like “Well known exploit = Easily Available = Likely” or “Current Infection Vector in our organization = Currently Spreading = Almost Certain”.
In Summary, With the Incident Categorization and Severity rating, you can easily bucket an incident thereby completing the Incident Classification phase of CSIRT Framework.
Go Back or Proceed with Part 3 – Incident Handling